

Nach meinem letzten Beitrag über Integration Runtimes (IR) eingegangen bin, geht es nun um Features der Data Factory. Diese Features machen die Entwicklung von Data Flows um einiges einfacher und benutzerfreundlicher. Somit ist diese Variante besser als beispielsweise bei SQL Server Integration Services (SSIS). Speziell geht es um eine Interaktive ADF Data-Flow Entwicklung.
Debug Integration Runtime
Um das Debugging von Data Flows einzuschalten, muss man den Data Flow Debug Modus aktivieren. Da Data Flows von der ADF mithilfe von Apache Spark ausgeführt werden, benötigt man ein aktives Spark Cluster. Nur so kann man die meisten Data Flow Debug-Features verwenden.
Um den Data Flow Debug zu aktivieren, muss der gleichnamige Switch in der Menüleiste eingeschaltet werden. In dem sich öffnenden Dialog muss nun die IR ausgewählt werden, welche für das Spark Cluster verwendet werden soll. Bis das Cluster hochgefahren ist und man es verwenden kann, dauert es dann ein paar Minuten – der perfekte Moment, sich einen Kaffee zu machen ☕.
Da für das Debug Cluster eine VM in Azure bereitgestellt wird, zahlt man hier auch für jede Minute, in der das Cluster aktiv ist. Die Kosten sind auch hier abhängig von der Art der IR und der Anzahl der Kerne. Hier wird minutenweise abgerechnet. Das Debug Cluster fährt nach nicht-Verwendung nach einiger Zeit automatisch herunter. So kann man Kosten sparen.
Da für das Debug Cluster eine VM in Azure bereitgestellt wird, zahlt man hier auch für jede Minute, in der das Cluster aktiv ist. Die Kosten sind auch hier abhängig von der Art der IR und der Anzahl der Kerne und werden minutenweise abgerechnet. Das Debug Cluster wird nach einer Zeit automatisch heruntergefahren, wenn es über einen längeren Zeitraum nicht verwendet wurde, um Kosten zu sparen.
Data Preview
Was die Entwicklung von Data Flows um einiges erleichtert, ist das Data Preview Feature. Dieses Feature ermöglicht es, sich das Ergebnis jeder Transformation anhand eines Datenausschnittes anzeigen zu lassen:
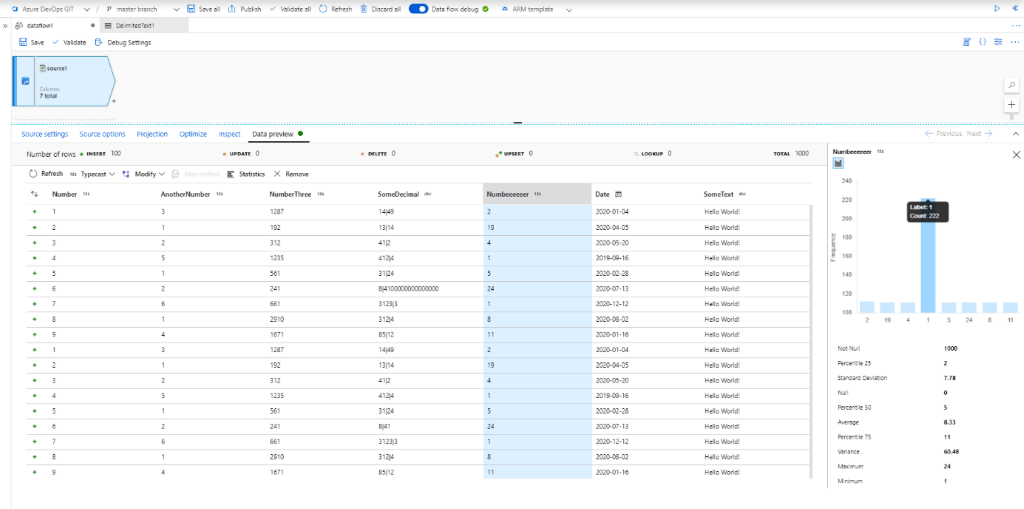
Die ADF lädt dafür ein Sample der Daten aus der Datenquelle. Im Anschluss lässt sie jegliche Transformation(en) bis zur gewünschten Transformation mithilfe des Debug Clusters ausführen.
So lassen sich die Ergebnisse der einzelnen Transformationen schon während der Entwicklung begutachten. Zusätzlich dazu lassen sich zu einzelnen Spalten Statistiken anzeigen. Somit erhält man einen ungefähren Eindruck von den Daten, mit denen man arbeitet.
Von der Data Preview aus lassen sich auch einfache Anpassungen vornehmen. Dazu zählen beispielsweise das Entfernen von Spalten, Typ-Konvertierungen oder simple Operationen wie das Runden von Zahlen. Diese Anpassungen können dann von der Data Preview aus übernommen werden. Die ADF erstellt für diese dann automatisch die entsprechenden Transformationen.
Expression Builder
Einer der schrecklichen Dinge in SSIS war der schlimme und in die Jahre gekommene Expression Builder. Dieser kommt beispielsweise bei abgeleiteten Spalten (Derived Columns) zum Einsatz.
Mit diesem ist der Expression Builder der ADF nicht mehr ansatzweise zu vergleichen:
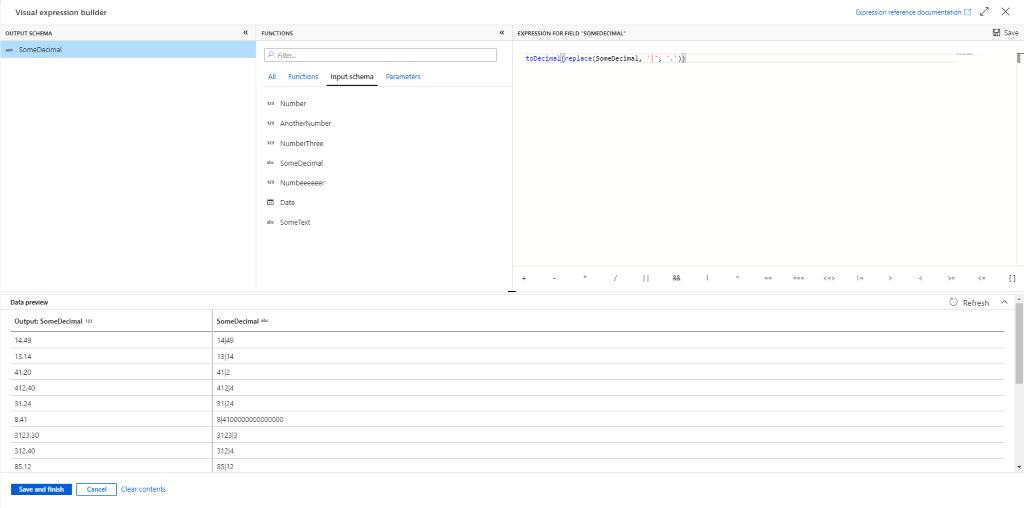
Über eine ordentliche Suchfunktion lassen sich Expressions, verfügbare Spalten und Parameter schnell finden. Ebenso ist der Editor auf der rechten Seite mit IntelliSense und Syntax-Hervorhebung ausgestattet. Dadurch verliert man auch bei komplexeren Expressions nicht so schnell die Übersicht.
Das für mich beste Feature des Expression Builders ist jedoch die Möglichkeit, sich eine Vorschau seiner Expressions anzeigen zu lassen. So kann man schon während der Entwicklung sehen, ob die erstellte Expression korrekt ist, oder ob die Daten, unsauber sind. ?
Anmerkung: Für diese Data Preview wird ein aktives Debug Cluster benötigt.
Datentyp Erkennung
Probleme gibt es wenn man mit Quellen arbeitet, die vorgegebene Datentypen besitzen. Ein Beispiel dafür sind CSV-Dateien. Man muss nämlich den Datentyp jeder Spalte explizit angeben. Alternativ muss man jede Spalte, die kein String ist, in den gewünschten Datentyp transformieren.
Die Data Factory erlaubt es den Datentyp solcher Quellen automatisch zu erkennen. Dafür wird das aktive Debug Cluster verwendet und ein Sample der Quelle eingelesen. Für simple Quellen wie CSV-Dateien kann der Detect data type Button verwendet werden. Für komplexere Dateitypen wie Apache Avro muss der Import projection Button verwendet werden. Der Grund dafür ist, dass das Schema für solche Daten nicht im Data Set selbst definiert ist. Die Schemata sind im Data Set selbst definiert.

Auf diese Weise lassen sich jedoch nicht immer alle Datentypen erkennen, was meistens dem Format der Daten geschuldet ist. Die Datentypen Date bzw. Time können oft nicht erkannt werden, da das Datumsformat nicht eindeutig identifiziert werden kann. Es ist jedoch auch möglich, den Datentyp jeder Spalte händisch über die entsprechenden Dropdown-Menüs zu ändern. Das passende Format kann ebenfalls angegeben werden – z.B. das tolle amerikanische Datumsformat MM-dd-yyyy ?.
Schlusswort
Die Data Factory bietet ein paar nette Features. Zum einen kann man die Data Flow Entwicklung vereinfachen. Zum anderen kann dies zu einer reduzierten Anzahl von Fehlern beitragen. Insbesondere das Data Preview Feature ist eines der größten Vorteile gegenüber von SSIS. Hier besteht die Möglichkeit seine Transformationen direkt einzusehen. So muss man nicht erst das Paket triggern, um sich die Daten anschauen zu können.



