

Data Flows
Im letzten Beitrag zur Azure Data Factory habe ich über die ein oder anderen Komponenten der ADF berichtet. Da ich den letzten Beitrag mit den DataFlows beendet habe, werde ich in dem jetzigen genau dort anknüpfen und etwas mehr ins Detail gehen. ADF Data Flows bringen nämlich viele Vorteile mit sich.
Data Flow Arten
Beim Anlegen eines Data Flows erscheint ein neues Fenster am rechten Rand des Bildschirms. In diesem Fenster wird man dazu aufgefordert eine Entscheidung zu treffen, ob man Mapping oder Wrangling Data Flows verwenden möchte. Hier stellt sich dann jedoch die Frage wo die Unterschiede liegen und für welchen Verwendungszweck sich welche Art besser eignet.
Mapping Data Flow
Bei den Mapping Data Flows liegt der Fokus auf der visuellen Transformation und der Logik der Daten. Die ADF übersetzt diese Transformationen im Hintergrund in Code, der aus Performance- gründen auf Azure Databricks Clustern ausgeführt wird. Dieses Prozedere ähnelt sehr stark der Erstellung von Data Flows in SSIS.
Wrangling Data Flow
Die Wrangling Data Flows werden verwendet, um die zugrunde liegenden Daten zu untersuchen und aufzubereiten. Der Fokus liegt dabei auf der Modellierung und Logik der Daten. Die Benutzer-oberfläche ähnelt sehr stark der des Power Query Editors. Hier werden die Transformationen in M-Code (Mashup) übersetzt und in einer Spark-Umgebung ausgeführt.
Abwägungssache
Alles in allem ist es auch eine Geschmacksfrage. Wenn man die beiden Arten der Data Flows genauer miteinander vergleicht, sieht man schnell einige Parallelen zwischen ihnen. Beispielsweise benutzen beide Arten die selben Quell- und Zielstrukturen (Azure Blob-Storage, Data Lake Storage…). Auch bei der Transformation der Daten werden sowohl bei Mapping- als auch bei Wrangling Data Flows Spalten umbenannt, Datensätze zusammengefügt etc.
Nun ist es neben der eigens präferierten Vorgehensweise so, dass es natürlich auch Szenarien gibt, bei denen es sich anbietet, sich gezielt zu entscheiden. Falls man unsicher sein sollte für welche Art man sich entscheiden soll, kann man diese Entscheidung auch vom eigentlichen Vorhaben abhängig machen.
Möchte man Fakten- und Dimensionstabellen beladen, bietet es sich an, die Mapping Data Flows zu verwenden. In diesem Fall sind sowohl das Quell- als auch das Ziel-Schema der Beladung bekannt. Zusätzlich hat man die Möglichkeit, sich der Funktionalität der Slowly Changing Dimension zu bedienen.
Möchte man hingegen ein neues Dataset erstellen und ist sich nicht ganz sicher, ob alle benötigten Daten vorhanden sind, bieten sich die Wrangling Data Flows an. Diese geben einen schnelleren und einfacheren Überblick über die zugrunde liegenden Daten.
Beispiel: Mapping Data Flow
So viel zur Theorie. Nun werde ich einen kleinen Einblick in das Innere der Mapping Data Flows gewähren. In diesem Beispiel werde ich zeigen, wie wir zuvor angelegte Datasets verwenden um Daten aus einer Flat-File im .csv-Format in die Datenbank zu laden.
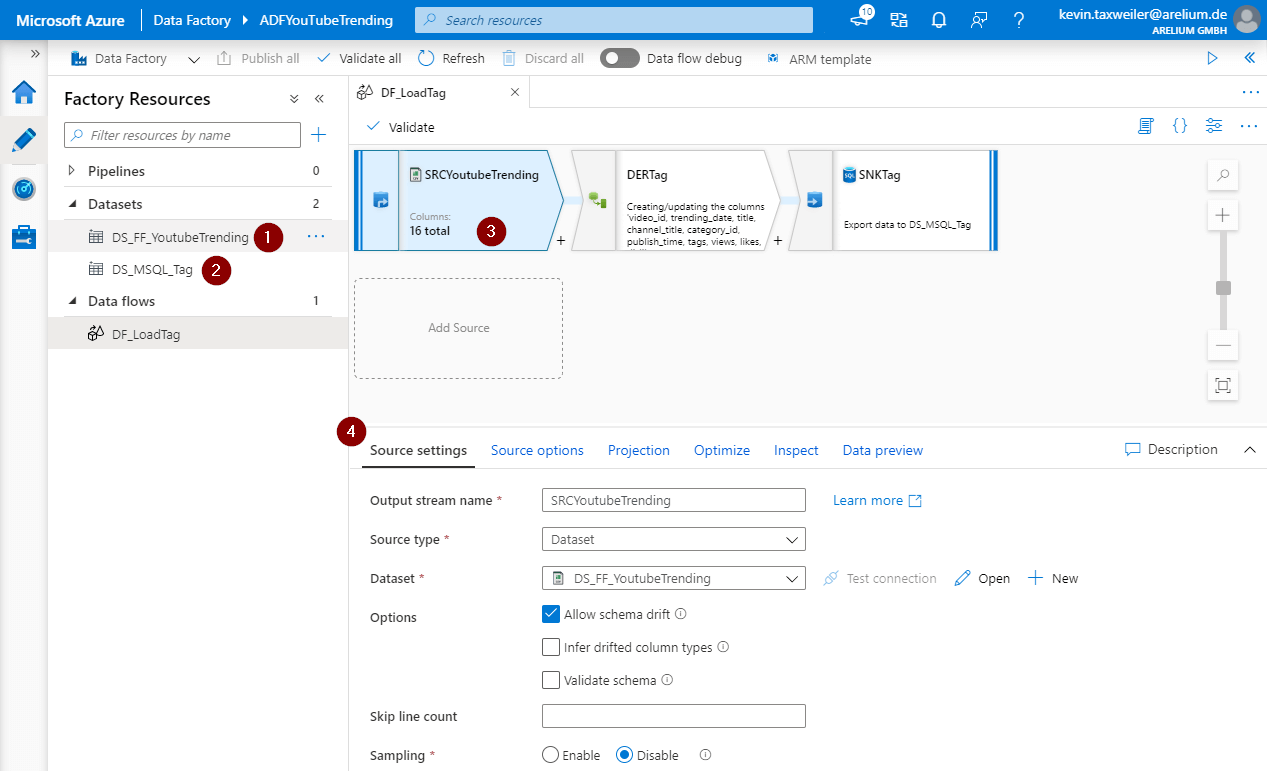
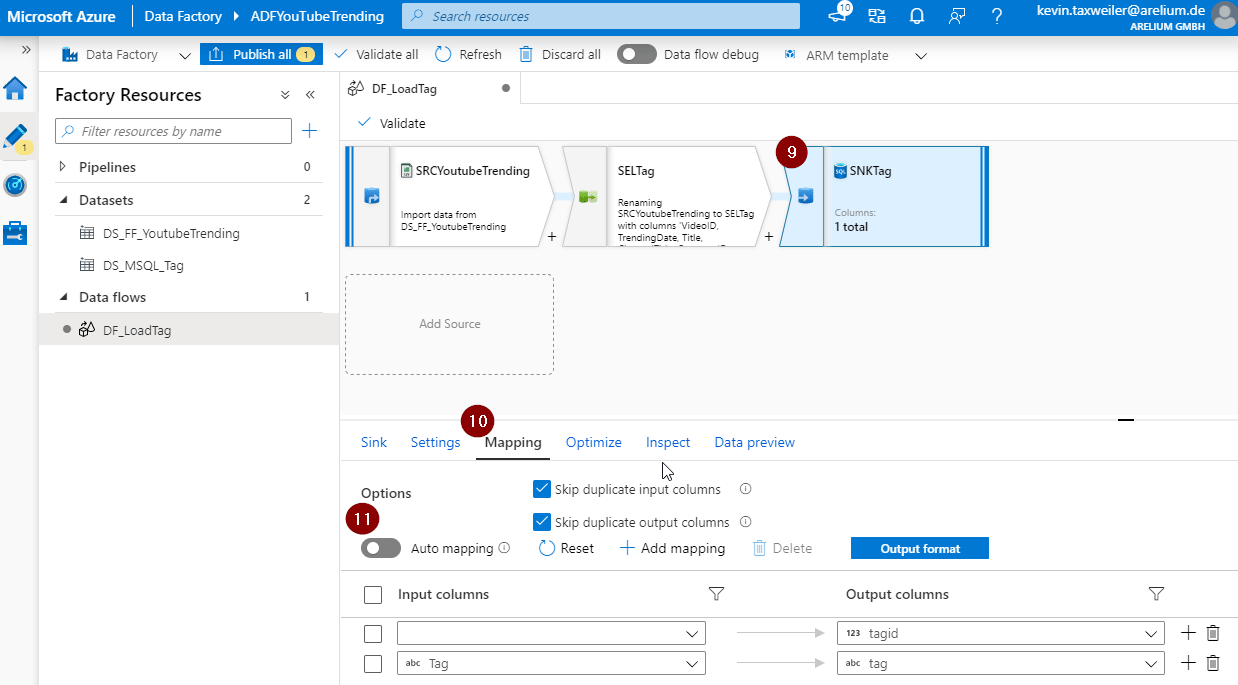
Wie Ihr in dem Bild sehen könnt, habe ich bereits einen Data Flow erstellt. Auf der linken Seite habe ich die beiden bereits erzeugten Datasets mit nummerierten Badges versehen. Das Dataset mit der Ziffer 1 beinhaltet die Struktur bzw. die Daten unserer csv-Datei. Das darunterliegende Dataset beinhaltet die Struktur unserer Datenbanktabelle mit dem Namen Tag. Dieses benötigen wir später um die Daten in unsere Datenbank zu schreiben. Die Punkte 3 und 4 zeigen uns die Data Flow Quelle. In diesem Beispiel bedienen wir uns an dem Dataset DS_FF_YoutubeTrending, welches auf einer csv-Datei basiert. Im durch die Nummer 4 gekennzeichneten Bereich sehen wir „Bedienoberfläche“ unserer angelegten Quelle. An dieser Stelle benennen wir unsere Quelle und geben an, von welchem Typ unsere Quelle sein soll. In diesem Fall ist es ein Dataset. Des Weiteren stehen allerdings auch XML, Excel und Delta zur Verfügung. Kommen wir zu den Menüpunkten in unserer Source.
weitere Einstellungen
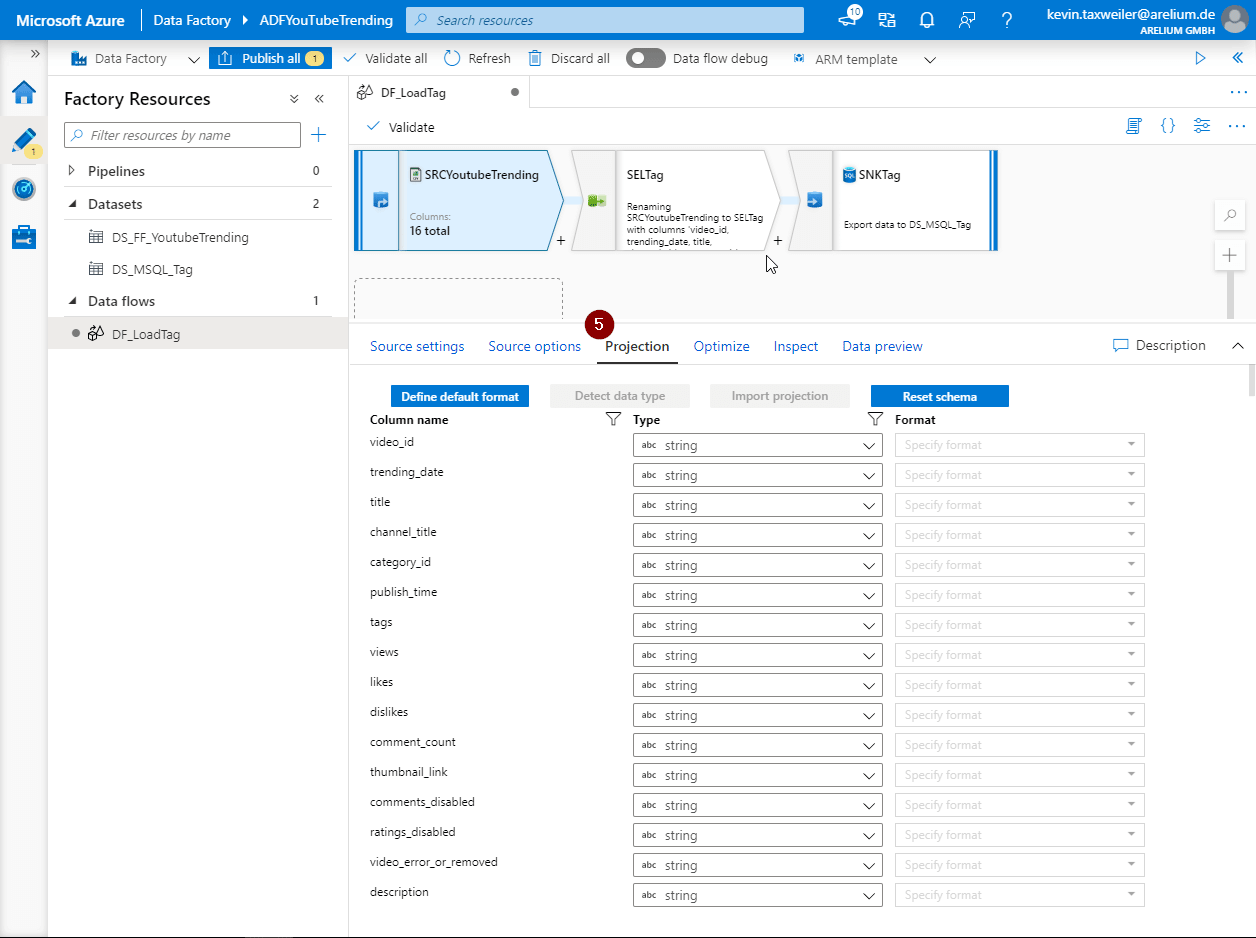
Wie ihr sehen könnt, zeigt der Reiter „Projection“ uns die Spaltennamen aus unserem Dataset. Die Spaltennamen sind weder praktisch noch optisch ansprechend. Aus diesem Grund bediene ich mich im nächsten Schritt an der Liste der Transformation (6) und wähle die Select-Transformation (7) aus.
die SELECT-Transformation
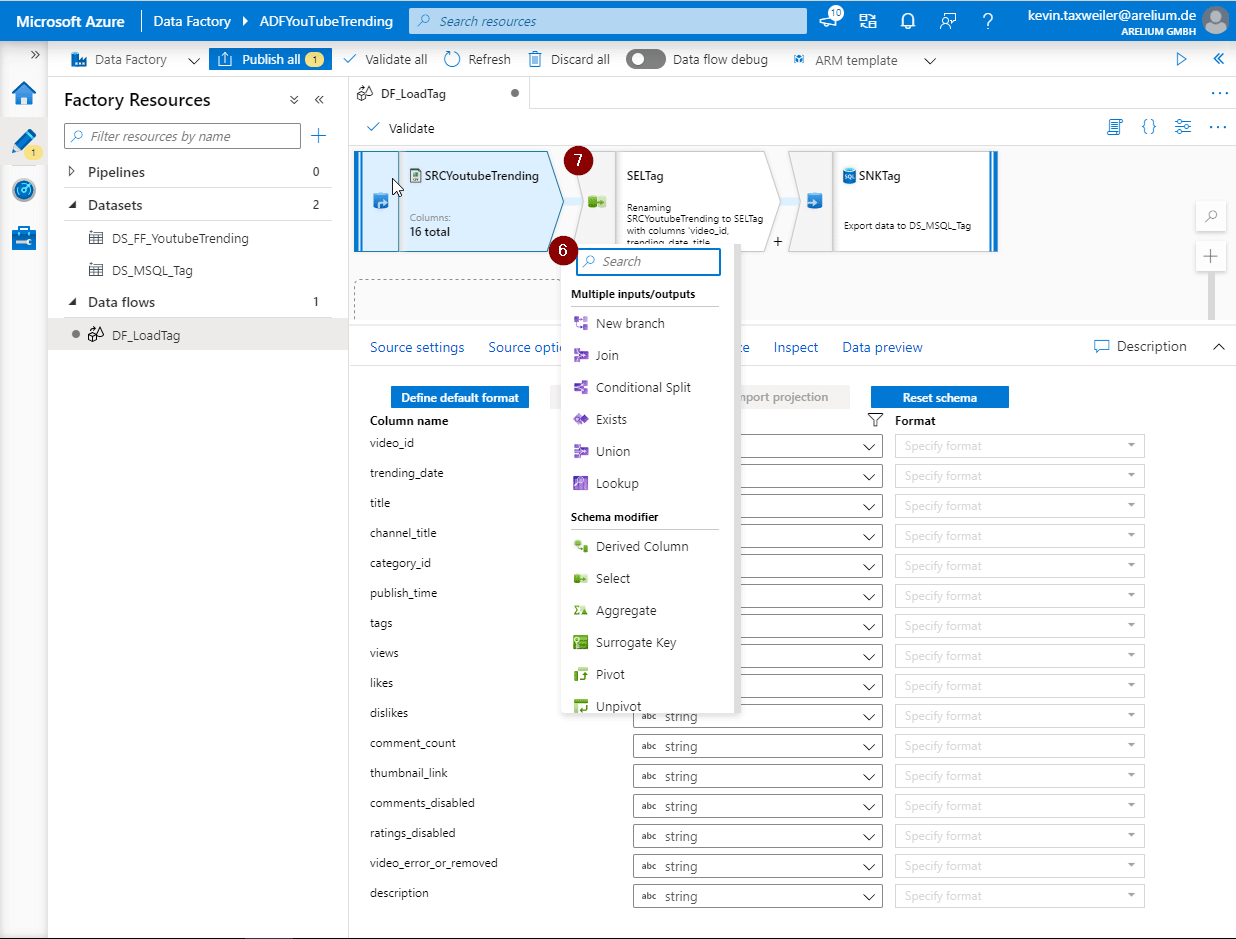
Die Select Transformation (7) bietet uns die Möglichkeit, die eingehenden Spalten anders zu benennen, zu duplizieren und das Duplikat unter einem anderen Namen im weiteren Verlauf des Data Flows mitzunehmen oder vorhandene Spalten zu löschen (8).
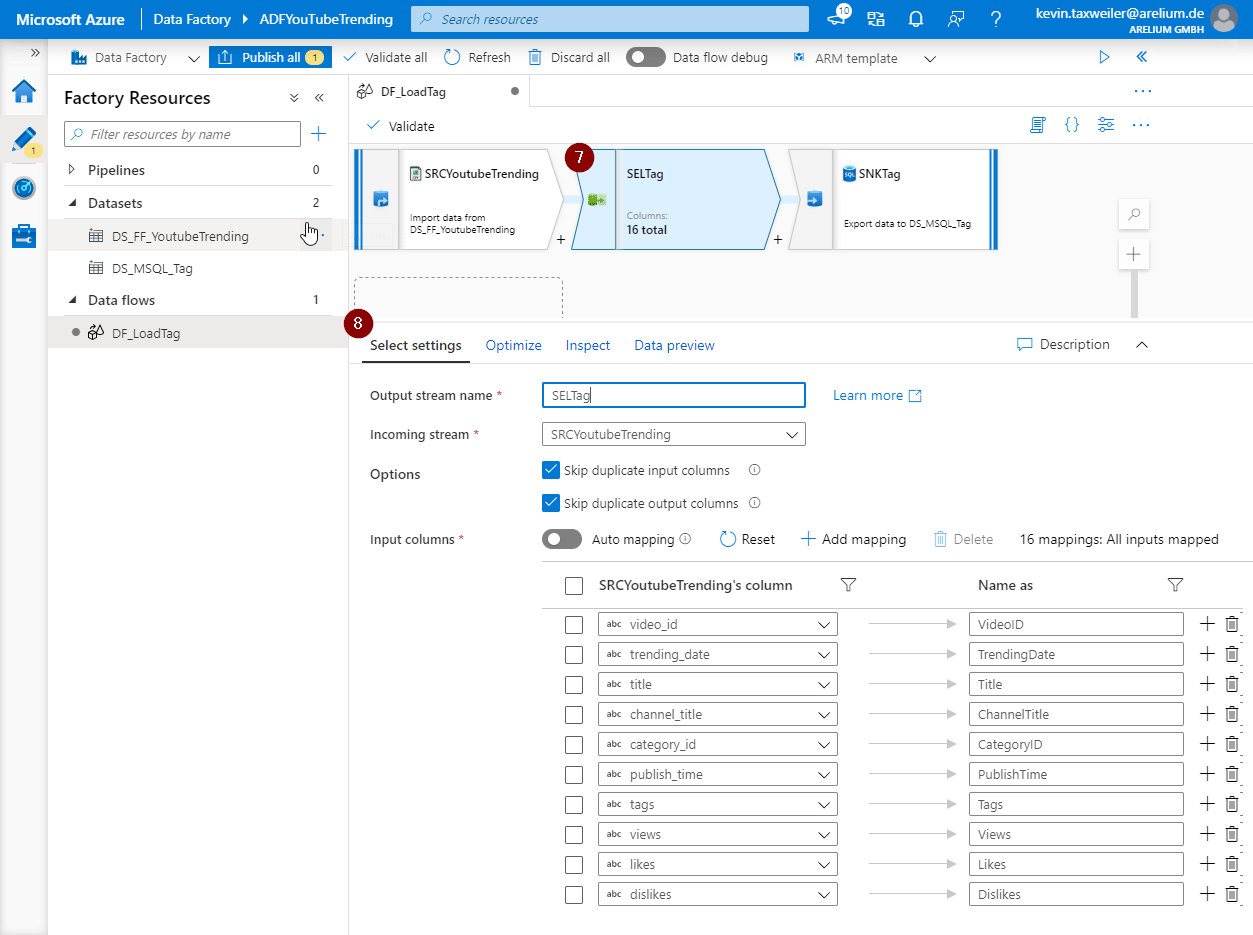
Spalten umbenennen
Die Umbenennung von Spalten ist insofern praktisch, weil man bei identischer Benennung von Input- und Zielspalten im Ziel-Dataset (9) unter dem Reiter Mapping (10) von der Möglichkeit des Automappings (11) profitiert. Das Ziel unseres Data Flows ist die SNKTag, welche durch das zu Beginn gezeigte zweite Dataset direkt auf unsere Tabelle in der Datenbank verweist. Hier sieht man, dass die Spalte TagID nicht zugeordnet wird. Zugegebenermaßen wäre dies auch durch eine manuelle Zuordnung nicht möglich, bot sich jedoch für dieses Beispiel prima an. Die Ursache dafür liegt ganz einfach darin, dass unsere Quelle diese Spalte gar nicht beinhaltet.
Was erwartet euch im nächsten Beitrag?
In meinem dritten Teil über die Azure Data Factory bin ich näher auf die Data Flows und deren Arten bzw. Anwendungsmöglichkeiten eingegangen. Im nächsten Teil der Blog-reihe über die Azure Data Factory werde ich genauer auf die Benutzung der Mapping Data Flows und die übrigen Transformationsmöglichkeiten eingehen, die Funktionsweise der dort verwendeten Komponenten näher erläutern und eventuell auch auf den ein oder anderen besonderen Kniff eingehen. Bis dahin eine angenehme Zeit und bleibt gesund.
PS: Gerne dürft Ihr uns eure Fragen, Themenvorschläge oder sonstige Anregungen zukommen lassen.



