
Einleitung
In dieser Blogreihe werde ich euch die Mapping Data Flows der Azure Data Factory (ADF) vorstellen. Diese wurden mit der V2 verfügbar gemacht. Zu Beginn gehe ich s auf die grundlegenden Konzepte ein. Danach werde ich in den folgenden Blog-Einträgen genauer auf einzelne Komponenten der Data Flows eingehen. Dazu gehören unter anderem die Funktionsweise und Features einzelner Data Flow Transformationen. Ich werde aber auch einen Blick hinter den Vorgang werfen und detailliert auf die dahinterliegende Struktur der Data Flows eingehen. Wie und wo wird zum Beispiel ein Data Flow gespeichert und was zum Henker ist das Data Flow Script ??
Without further do…
Part 1 – ADF V2 und die Geburt der Mapping Data Flows
Mit der Veröffentlichung der v2 der Azure Data Factory (ADF) Juni 2018 wurden der ADF einige dringend benötigte Features hinzugefügt. (V2 ist allerdings eher ein komplett neues Produkt im Vergleich zur V1). Ein großes Manko der ADF war es bis dahin, dass es nicht direkt möglich war, Daten effektiv zu verarbeiten. Es gab auch in V1 die Möglichkeit, Daten von A nach B zu kopieren oder eigens definierte ETL-Prozesse über beispielsweise Azure Databricks zu erstellen. Allerdings ist zur Verwendung dieser ein Know-How in Sprachen wie etwa Python, R oder Java von Nöten. Über die ADF direkt ließen sich somit eher nur ELT-Prozesse abbilden.
Diese Lücke wurde durch eines der wohl größten Features der v2 gefüllt – den (Mapping) Data Flows. Diese ermöglichen es erstmals, komplexe Datentransformationen in der ADF direkt zu erstellen, ohne beispielsweise Kenntnisse von Programmiersprachen zu benötigen. Somit ist es nun möglich, komplette ETL-Prozesse in Azure zu erstellen.
Bei der Struktur und dem Aufbau der Data Flows hat sich Microsoft sehr stark an SSIS orientiert. Somit finden sich Entwickler, die sich hauptsächlich mit SSIS beschäftigt haben, schnell zurecht.
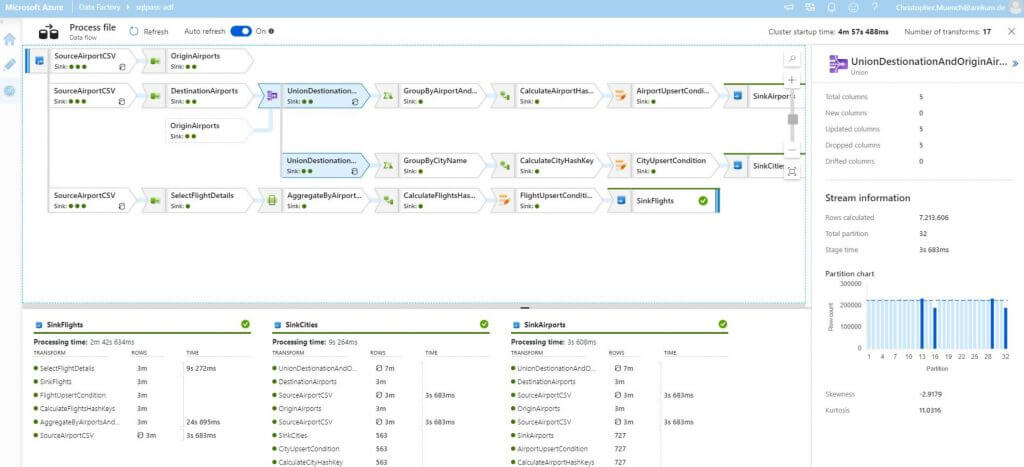
Wieso nicht einfach SSIS verwenden?
Mit der V2 wurde der ADF ebenfalls die Möglichkeit gegeben, SSIS Pakete über die Azure-SSIS Integration Runtime (IR) laufen zu lassen. Wieso sollte man also die neuen Data Flows verwenden?
Natürlich hat man durch die Rechenpower von Azure nahe zu unendliche Möglichkeiten, die IR zu skalieren. Somit ist es möglich die Ausführungsdauer seiner Pakete zu verringern. Allerdings zahlt man auch für jede Minute, in der die IR läuft. Um Kosten zu sparen lässt sich die IR pausieren und vor Ausführung eines Paketes wieder hochfahren. Andererseits kostet das Hochfahren der IR auch Zeit und wird bei zunehmender Anzahl von auszuführenden Paketen schwer realisierbar. Man zahlt also oft sehr viel für die reservierte Hardware, während diese im Idle-Modus schlummert. Gerade bei hardwaremäßig stärkeren Instanzen können so sehr schnell hohe Kosten entstehen.
Data Flows als moderne Alternative zu SSIS
Bei den Data Flows setzt Microsoft auf eine komplett andere Strategie. Die IRs, die für die Ausführung von Data Flows in der ADF verwendet werden, sind allesamt virtuelle Maschinen (VM). Diese werden nur für die Ausführung bereitgestellt werden und im Anschluss wieder heruntergefahren. Man zahlt demnach nur für die Zeit, für die die virtuelle Maschine wirklich läuft.
Um die Transformationen eines Data Flows auszuführen, verwendet die ADF im Apache Spark Cluster, welche in den VMs laufen. Durch die Verwendung von Spark zeigt Microsoft auch direkt, wofür die Data Flows ausgelegt sind: Die möglichst effiziente und schnelle Verarbeitung von Datenmengen im Big Data Bereich.
Als Entwickler muss ich mir nun jedoch keinerlei Gedanken darüber machen, wie meine ETL-Prozesse in Spark ausgeführt werden. Ich muss ebenfalls keine neue Sprache lernen. Das Einzige, was man sich aneignen muss sind die Data Flow Expressions. Aber hey, das musste man sich in SSIS auch aneignen. Mit einer halbwegs ordentlichen Dokumentation und einem ordentlichen Expression-Builder (welcher auf Microsofts Monaco Editor basiert), bei dem man sich nicht die Haare aus dem Kopf reißen will – insofern noch welche vorhanden sind – macht das Erstellen komplexer Expressions sogar Spaß!
Zusätzlich dazu lässt sich für jeden Data Flow individuell die Hardware für die VMs einstellen. Sollen dies beispielsweise nur vier Kerne für überschaubare oder bis zu 256 (!) Kerne für riesige Datenmengen sein? Dies lässt sich für jeden Data Flow einzeln und individuell einstellen. Ebenso muss man sich keinerlei Gedanken um die Verwaltung dieser VMs oder sonstige Dienste machen. All das erledigt die ADF für einen. Ausgenommen ist eine SQL-Datenbank, die je nach Leistung der VM schnell zu einem Bottleneck werden kann ?.
Schlusswort
Mit den Mapping Data Flows hat Microsoft der Azure Data Factory eine wirklich moderne und gut funktionierende Lösung zur Entwicklung moderner ETL Prozesse gebaut. Diese eignet sich nicht nur für kleine, sondern auch für riesige Datenmengen.
In meinem nächsten Blogeintrag werde ich genauer auf die Funktionsweise der Integration Runtime eingehen, die für die Data Flows verwendet werden. Außerdem werde ich ein paar Techniken vorstellen, um die Kosten und die Laufzeit einzelner Data Flows so gering wie möglich zu halten.



