In diesem Beitrag geht es um die Azure Data Factory Integration Runtimes (IR). Diese verwendet man für die Mapping Data Flows, um Datentransformationen auszuführen.
Wie bereits im vorherigen Blogpost erwähnt, wird für die Ausführung der Data Flows ADF Spark verwendet. Dies läuft auf virtuellen Maschinen (VM). Daher muss ich mir als User über das aufsetzen der VMs keinerlei Gedanken machen. Ich muss lediglich die Frage des Typs der VM beantworten.
Und genau das ist im Prinzip eine IR – eine Definition einer virtuellen Maschine, in der die folgenden Fragen beantwortet werden:
- In welcher Region sollen sich die VMs dieser IR befinden?
- Für welchen Zweck sollen sie optimiert sein?
- Wie viele (virtuelle) Kerne sollen sie haben?
- Wie lange soll eine VM nach ihrer Ausführung weiter existieren (TTL, dazu später mehr)?
Integration Runtimes Übersicht
Eine Übersicht aller IR kann man sich auf der Benutzeroberfläche der ADF unter dem Menüpunkt Connections > Integration Runtimes anzeigen lassen. Folglich kann man diese von dort auch anlegen:
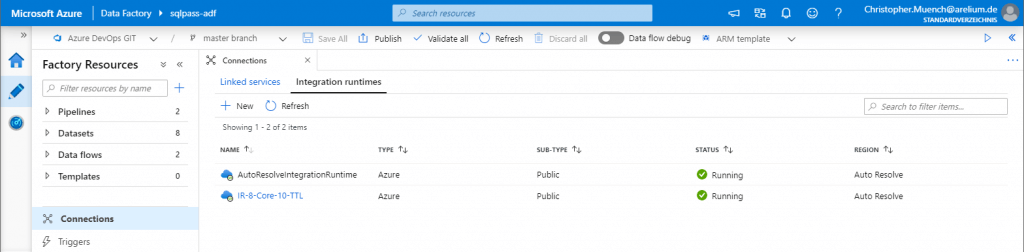
Die Integration Runtime mit dem Namen „AutoResolveIntegrationRuntime“ ist immer verfügbar und kann dynamisch beim Aufrufen eines Data Flows konfiguriert werden. Ein Beispiel dafür wird später zu sehen sein.
Jede selbst definierte IR hat festgelegte Einstellungen, die man – mit Ausnahme der Beschreibung & der Region – nachträglich nicht mehr ändern kann.
Neue Integration Runtime anlegen
Über den New-Button lässt sich eine neue IR erstellen. Dadurch öffnet sich auf der rechten Seite ein Overlay, in dem man die Art der IR auswählen muss. Dort wählt man Azure, Self-Hosted aus und im nächsten Dialog Azure.
Anmerkung: Azure bietet die Möglichkeit, eigene On-Premise (Self Hosted) Server an die ADF anzubinden. Diese kann man jedoch nicht verwenden um Data Flows auszuführen. Sie werden benötigt, wenn man auf Ressourcen zugreifen will die Azure nicht erreichen kann. Beispielsweise private Netzwerke.
Hat man alles richtig gemacht, sollte folgendes Fenster sichtbar sein:
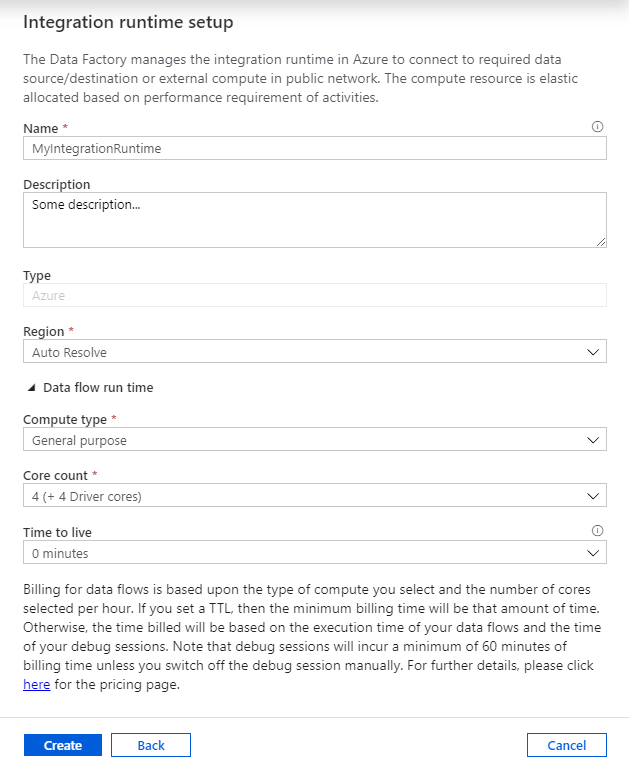
Einstellungssache
Während Name und Description selbsterklärend sein sollten, sind die unteren vier Optionen die interessanten. Sie spiegeln die Antworten wider, die ich zu Beginn dieses Beitrages aufgelistet habe:
- Region: Bestimmt die Region, in der VMs dieser IR erstellt werden sollen. Ist der Standardwert Auto Resolve gesetzt, erstellt Azure VMs in der selben Region in der auch die ADF liegt.
- Compute type: Gibtdie Optimierungsgrundlage der VMs von der IR an:
- Compute Optimized
eignet sich für Data Flows, die viel rechnen müssen und sind mit ca. 0,17€ pro vCore-hour am preiswertesten. - Memory Optimized eignet sich für große Datenmengen, sodass Spark mehr Daten im Arbeitsspeicher cachen kann. Da dafür entsprechend mehr RAM benötigt wird, sind diese mit ca. 0,29€ pro vCore-hour am teuersten.
- Der Standardwert General purpose ist eine Mischung aus den beiden oberen Optionen und sollte in den meisten Fällen ausreichend sein. Mit ca. 0,23€ pro vCore-hour liegt ihr Preis zwischen den beiden anderen.
- Core count: Definiert die Anzahl der Kerne, welche der VM zur Verfügung stehen. Man
wählt man zwischen acht und 272 Kerne aus. Hier bekommt der oben verwendete Begriff vCore-hour Bedeutung. Anhand diesem lassen sich die ungefähren Kosten für die Ausführung des Data Flows errechnen:
Anzahl Kerne (vCore) * Computetype Preis * Laufzeit der VM in Stunden
Anmerkung:
Je nachdem, was der Data Flow macht, können natürlich noch weitere Kosten für andere
Azure-Dienste wie Datenbanken, Storage etc. anfallen.
Alle angezeigten Kosten beziehen sich auf den Stand von Mai. 2020, die aktuellen
Kosten können in der Data Pipeline Pricing Übersicht entnommen werden.
- Time to live: Mit der TTL-Option wird eingestellt, wie lange eine VM dieser IR nach ihrer Ausführung warm bleiben soll. Ist dieser Wert größer als 0, wird die VM nicht sofort heruntergefahren. Somit kann man diese für weitere Data Flows verwenden.
Aufrufen eines Data Flows
Über eine Pipeline kann man einen Data Flow über die Data Flow
Activity aufrufen. In den Einstellungen der Activity muss man neben dem
auszuführenden Data Flow auch die IR auswählen , die verwendet werden
soll – hier kommt die AutoResolveIntegrationRuntime ins Spiel.
Wird diese ausgewählt, kann man Compute type und Core
count dynamisch einstellen. Es können Pipeline
Expressions verwendet werden oder die Einstellungen lädt man beispielsweise
über eine Lookup-Activity aus einer Datenbank.
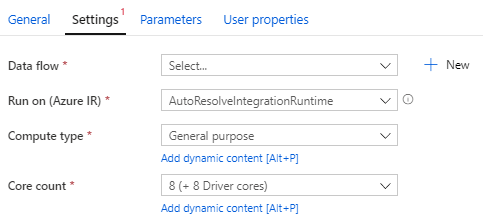
Wählt man eine eigens definierte IR aus, lassen sich diese
Einstellungen nicht mehr anpassen. Doch wieso sollte man dann überhaupt eigene
IR definieren, wenn die wichtigsten Einstellungen auch hier vorgenommen werden
können ??
Hier kommt die TTL-Einstellung ins Spiel, die es bei der AutoResolveIntegrationRuntime nicht gibt.
„Time to Live“ – Einstellung
Mit der Time to Live Einstellung wird definiert, wie
lange eine VM einer IR nach Durchführung eines Data Flows warm – also am
Leben – bleiben soll. Auf den ersten Blick sieht diese Funktion kontraproduktiv
aus, denn solange die VM hochgefahren ist, produziert sie Kosten. Doch so
unnütz ist diese Funktion nicht – sonst hätte sie Microsoft wohl nicht
implementiert ?.
Soll ein Data Flow ausgeführt werden, schaut die ADF als
allererstes, ob es bereits eine warme, untätige VM im Pool gibt, die zur
Ausführung des Data Flows verwendet kann und mit den Einstellungen der IR
übereinstimmt. Ist dies der Fall, muss lediglich ein neues Spark-Cluster
bereitgestellt werden, was zwischen einer bis zwei Minuten dauert.
Wird keine warme IR in diesem Pool gefunden, muss natürlich vorerst
eine neue VM erstellt werden. Zwar produziert das Hochfahren einer VM keine
Kosten, allerdings dauert dies im Durchschnitt etwa fünf Minuten. Hinzu kommt
noch die Zeit, die benötigt wird, um das Spark-Cluster zur Verfügung zu
stellen. Es dauert also zwischen sechs und sieben Minuten, bis der Data Flow
letztendlich verarbeitet werden kann.
Führt ein ETL-Prozess also mehrere Data Flows sequenziell
aus, lässt sich die Gesamtlaufzeit durch Verwendung der TTL-Einstellung bemerklich
verringern ?.
Schlusswort
Zusammenfassend lässt sich mit Hilfe von Integration Runtimes auf eine einfache Art bestimmen, mit welcher Hardware man einen Data Flow ausführen soll. Um die eigentliche Bereitstellung der virtuellen Maschinen und deren Spark Cluster muss man sich als Entwickler jedoch keinerlei Gedanken machen. So lässt sich die Hardware, die man zur Ausführung eines Data Flows verwendet, ohne große Probleme hoch- bzw. runterskalieren. Dies geschieht, indem man dem Data Flow einfach eine andere Integration Runtime zuteilt.
Nachdem ich in diesem Beitrag auf die Integration Runtimes eingegangen bin, werde ich im nächsten Beitrag auf die Interaktive Data Flow Entwicklung eingehen und zeigen, welche Möglichkeiten zum Debugging und Testen die Data Factory ebendieser bereitstellt.